Duplikatencheck
Der Duplikatencheck kann auf zwei verschiedene Arten eingesetzt werden:
- Adressen direkt nach dem Erfassen der Daten auf Duplikate prüfen (Menupunkt Duplikatencheck während Erfassung = Ja).
- Duplikatencheck über alle oder selektierte Adressen innerhalb Ihres Adressstammes (Menupunkt 3.1)
Der Duplikatencheck des europa3000™-Systems kann mit definierbaren Parametern, den sogenannten Feldtoleranzen gesteuert werden.
Was sind Feldtoleranzen?:
Unter Feldtoleranzen versteht man die Anzahl Abweichungen in einem Eingabefeld, die das Programm akzeptiert, um beim Vergleich zweier Adressen diese als identisch zu erkennen. Dies kann eine grosse Hilfe sein, denn oft kennt man nur die phonetische Schreibweise eines Namens. So ist das Programm z.B. in der Lage, um
"Lehner Karl ",
"Leener Carl",
"Lener Carl"
als denselben Namen zu identifizieren, wenn für die Person, deren Namen dreimal in je einer der obigen Schreibweise erfasst ist, die restlichen Adressdaten wie die Strasse, Hausnummer und Ortschaft innerhalb der für diese Felder eingestellten Toleranzen übereinstimmen.
Da das Programm nicht beurteilen kann, was (aufgrund der erkannten Toleranzen) ein wirkliches und was ein vermeintliches Duplikat ist, löscht die Duplikatencheck keine Adressen, sondern die identisch erkannten Adressen werden auf einem Drucker, auf dem Bildschirm oder in einer Datei gedruckt. damit Sie selbst entscheiden können, welche Adressen verschiedene Personen oder dieselbe Person betreffen.
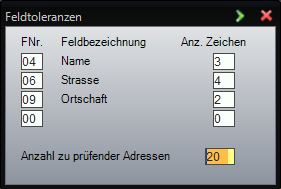
Die Feldtoleranzen können Sie im Menupunkt Parameter Duplikatencheck definieren:
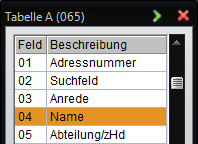
Mit der Funktionstaste 'F1' erhalten Sie die zur Verfügung stehenden Felder:
Standardmässig sind die oben abgebildeten Werte eingestellt. Sie können durch Überschreiben geändert werden.
FNr. (Feldnummer):
Programmintern hat jedes Feld eine Nummer, die in dieser Spalte eingetragen sein muss, wenn das beteffende Feld in den Duplikatencheck miteinbezogen werden soll. Hier die wichtigsten Feldnummern:
Adressnummer = 01
Anrede = 03
Name/Firmenname = 04
Abteilung/z.Hd. = 05
Strasse/Nummer = 06
PLZ / Ortschaft = 09
Code 1 = 16
Code 2 = 17
Code 1 = 18
Code 2 = 19
Feldbezeichnung:
Text in den drei Systemsprachen, der den betreffenden Eingabefeldern vorangestellt ist.
Anz. Zeichen:
Die Zahl, die hier eingegeben wird, bestimmt, wie viele Zeichen bei zwei Adressen im betreffenden Feld voneinander abweichen dürfen, damit das Programm die beiden Adressen als identisch erkennt, falls die übrigen Adressdaten innerhalb der eingestellten Feldtoleranzen übereinstimmen.
Anzahl zu prüfender Adressen:
Gibt an, wieviele Adressen in Folge ab der aktuell zu prüfenden Adresse verglichen werden sollen. Generell gilt: Je mehr Adressen in Ihrem Stamm vorhanden sind, desto grösser sollte dieser Wert sein. Je mehr Adressen in Folge geprüft werden, desto länger dauert der Duplikatencheck. Erfahrungsgemäss ist ein Wert von 50 Adressen für Datenbestände mit bis zu 10'000 Adressen ausreichend.
Die Gross-/Kleinschreibung spielt beim Vergleich der Adressdaten ausser bei den Anfangsbuchstaben keine Rolle. Jedes Leerzeichen gilt als genau ein Zeichen.
Beispiel 1:
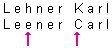
In diesem Beispiel weichen genau die beiden Zeichen, die mit einem Pfeil bezeichnet sind, voneinander ab. Ist für das Namensfeld in der Spalte "Anz.Char:" eine «2» eingegeben worden, so erkennt das Programm diese zwei Adressen als gleich, wenn Strasse, Hausnummer und Wohnort innerhalb der eingestellten Toleranzen auch übereinstimmen.
Beispiel 2:
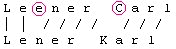
Auch in diesem Beispiel weichen genau zwei Zeichen, die mit einem Kreis gekennzeichnet sind, voneinander ab. Falls die restlichen Eingabefelder gleich sind, wird auch dieses Beispiel in die Duplikatencheck-Liste aufgenommen.
Hinweis für Servicepartner:
Bitte beachten Sie, dass Adressdaten im Duplikatencheck immer nach dem zweiten Keyfeld gelesen werden (Feld A04, respektive Feld A02, wenn dieses als Keyfeld parametriert worden ist). Setzen Sie also nebst der Adressnummer keine Keyfelder vor das Feld A04, welche keine alphabetische Sortierung haben (Ausnahme Index A02).